Introducing Knowledge Assurance Protocols
18 June 2026·7 min read
This thinkpiece introduces Knowledge Assurance Protocols (KAP): a way of giving AI systems a clear set of rules for how knowledge should be received, structured and produced.
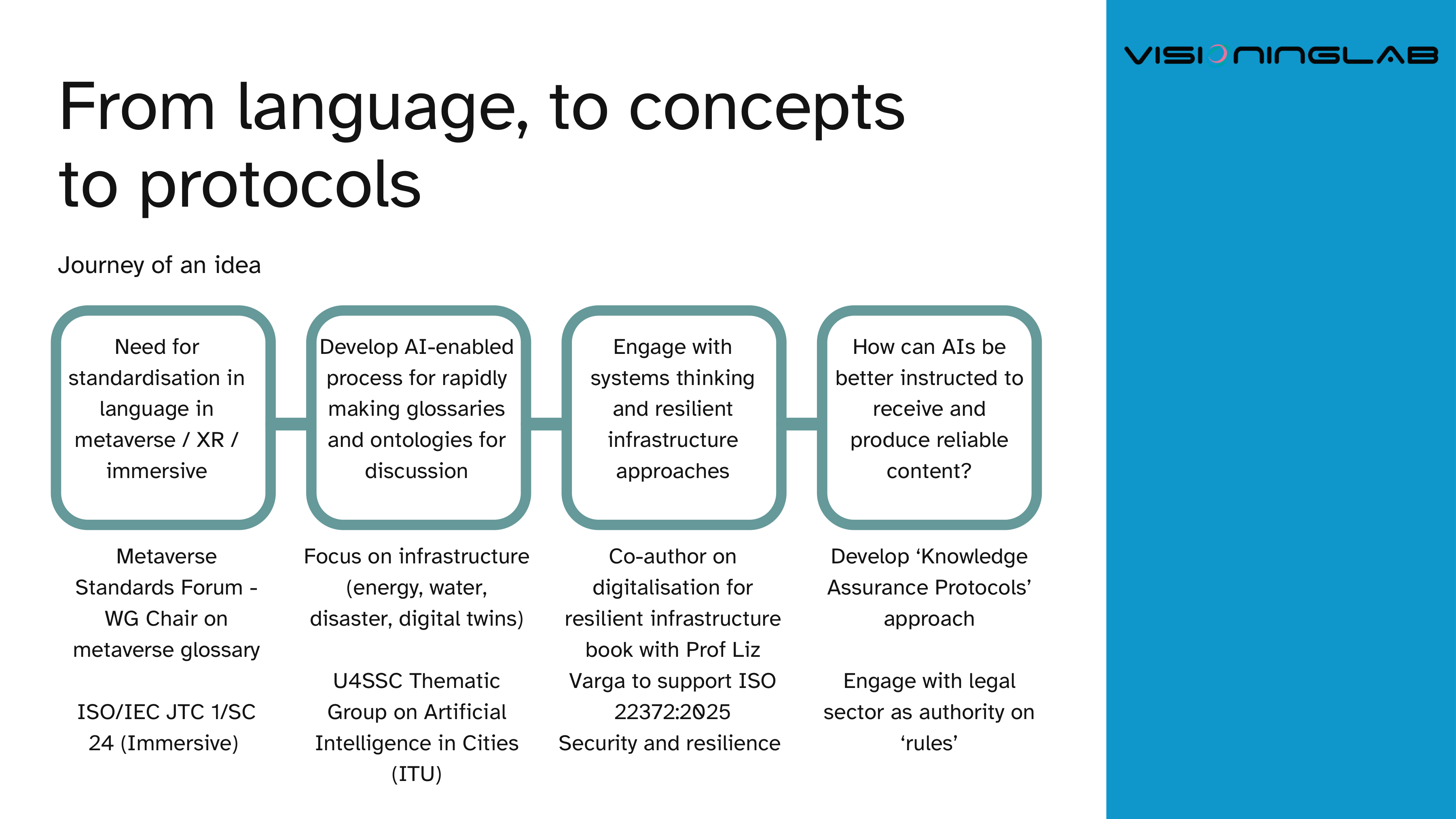
It comes out of a long thread of work. It started with a practical need for standardisation in language across the metaverse, XR and immersive industries, and grew into something broader.
From language, to concepts, to protocols
The journey moved through several stages. Chairing a working group on the metaverse glossary at the Metaverse Standards Forum, and engaging with ISO/IEC JTC 1/SC 24 on immersive standards, made the language problem concrete.
That led to building an AI-enabled process for rapidly making glossaries and ontologies for discussion — work that touched infrastructure such as energy, water, disaster recovery and digital twins, including with the U4SSC Thematic Group on Artificial Intelligence in Cities at the ITU.
From there the thread ran through systems thinking and resilient infrastructure, co-authoring on digitalisation for resilient infrastructure to support ISO 22372:2025, and engaging with the legal sector as an authority on rules.
The question that kept returning was this: how can AIs be better instructed to receive and produce reliable content?
The problem: data is a mess, and sharing is expensive
Three problems sit underneath this.
Data rests in silos, and digital is disjointed. Datasets are scattered across multiple formats, software, servers and local PCs. Many digital solutions sit behind proprietary black boxes.
People communicate at cross purposes. Different sectors use different terms for the same thing — one person's drone is another person's UAV. Miscommunication is expensive: in the workplace it is estimated to cost US businesses around $1.2 trillion every year, and a large share of project professionals spend much of their time on rework caused by unclear or misunderstood requirements.
AI models need mass data to train on. Those models are only as good as the source material they learn from, and that data needs to be significant.
Solutions we already use: ontologies, knowledge graphs and APIs
Some of this is well-trodden ground. Ontologies, knowledge graphs and APIs can make AI more efficient.
- Ontologies are standard data catalogues with pre-defined relationships that support efficient data management.
- Knowledge graphs are visualisations of ontologies — data and its relationships — that can be converted into software APIs.
- APIs connect software together so that data can flow smoothly.
Sectors that already lean on ontologies — agriculture, energy, biomedical, financial services — show what is possible. Newer or fast-moving sectors face the same need: the built environment with its sustainability pressures, the emerging metaverse industry, relationship management, and the legal sector with its highly specific and rapidly evolving terminology.
This is the work we do through Ontology Maker, an AI-assisted process that turns project documentation, glossaries, standards and open-source ontologies into a project glossary, through a feedback loop and a clear sign-off, ready in multiple languages and formats. It has produced energy glossaries for an EU car battery passport, water glossaries for continuous water quality monitoring, disaster recovery glossaries, and the metaverse glossary itself.
Connecting at a higher level: introducing KAPs
Glossaries and ontologies organise terms and relationships. A Knowledge Assurance Protocol works one level up.
A KAP provides a set of rules for ontologies, knowledge graphs and other data reconciliation processes.
It is not a platform, not an ontology, and not a dataset. It is a set of principles to be shared with an AI.
A KAP:
- governs how AI systems access and use knowledge, rather than being a platform in itself
- defines what counts as valid knowledge — sources, evidence and context
- structures knowledge using a shared semantic framework, without forcing everything into a single standard
- makes provenance, confidence and uncertainty explicit in every output
- constrains AI to produce traceable, comparable and accountable results
- preserves differences and disagreement, rather than smoothing them out
- enables consistent interpretation across datasets, languages and teams
It is deliberately a high-risk hypothesis: designed and tested through real use cases, partly to show the limits of AI in decision-making.
Because the rules sit above any one domain, KAPs can align parts of a whole. We are developing variants for biodiversity (BKAP) as a conceptual layer, water (WKAP) as a physical layer, and digital delivery (DKAP) as a delivery layer.
What a KAP looks like in practice
The diagram below shows BKAP — a protocol layer for trusted ecological AI — moving from diverse biodiversity knowledge to structured, uncertainty-aware decisions.
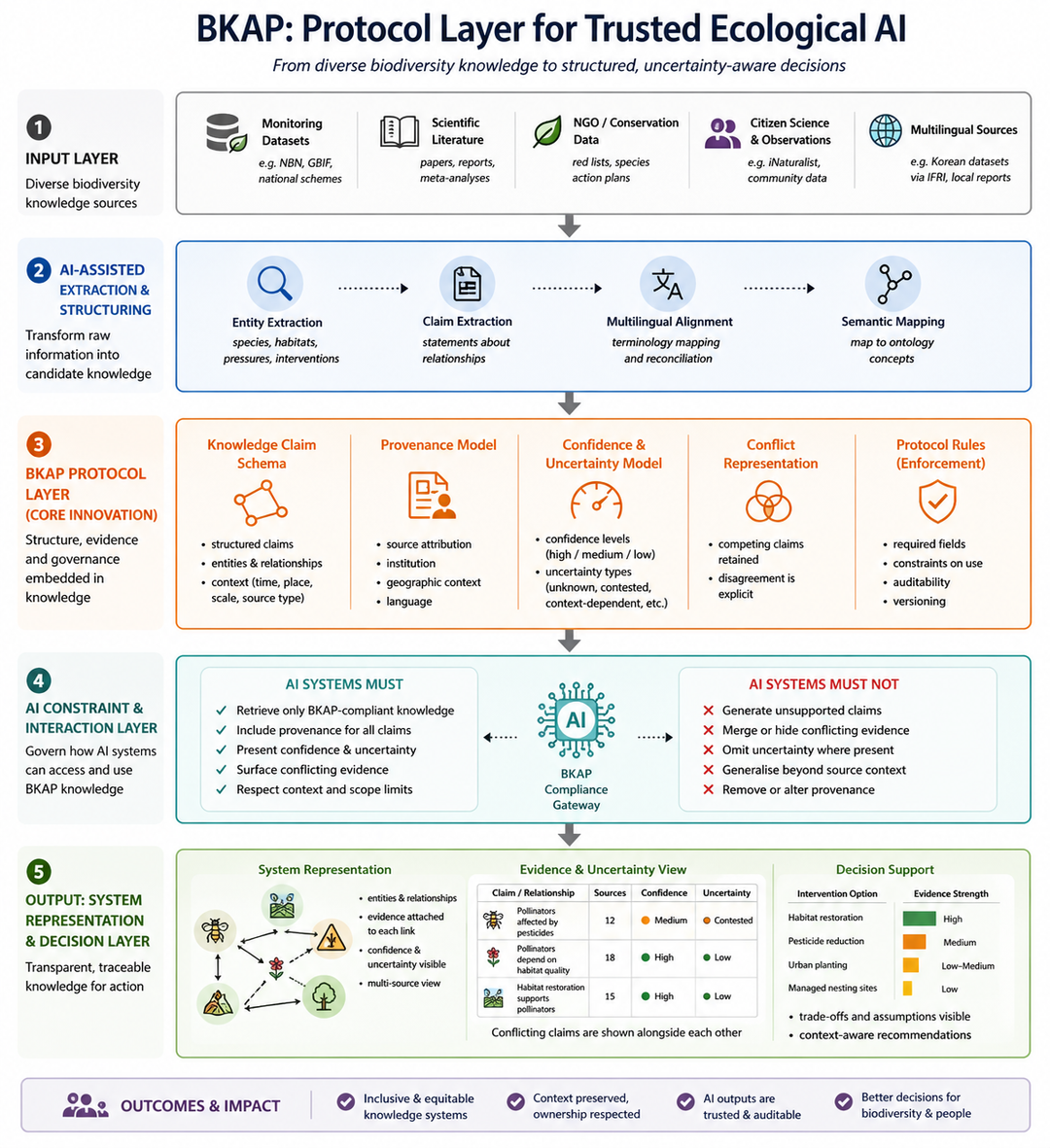
Knowledge enters from many sources — monitoring datasets, scientific literature, conservation data, citizen science and multilingual reports. AI then extracts entities and claims, aligns terminology across languages, and maps them to ontology concepts.
The protocol layer is the core. It holds the structured claims, attaches provenance and geographic context, records confidence and uncertainty, and keeps competing claims visible rather than merging them.
The constraint layer is blunt about what AI is allowed to do. AI systems must retrieve only protocol-compliant knowledge, include provenance for all claims, present confidence and uncertainty, surface conflicting evidence, and respect context and scope limits. AI systems must not generate unsupported claims, merge or hide conflicting evidence, omit uncertainty, generalise beyond the source context, or remove or alter provenance.
The output is a transparent, traceable view: entities and relationships with evidence attached to each link, confidence and uncertainty made visible, and decision support that shows trade-offs and assumptions rather than a single confident answer.
How a KAP is created
A KAP is built through six stages, with continuous governance running underneath.
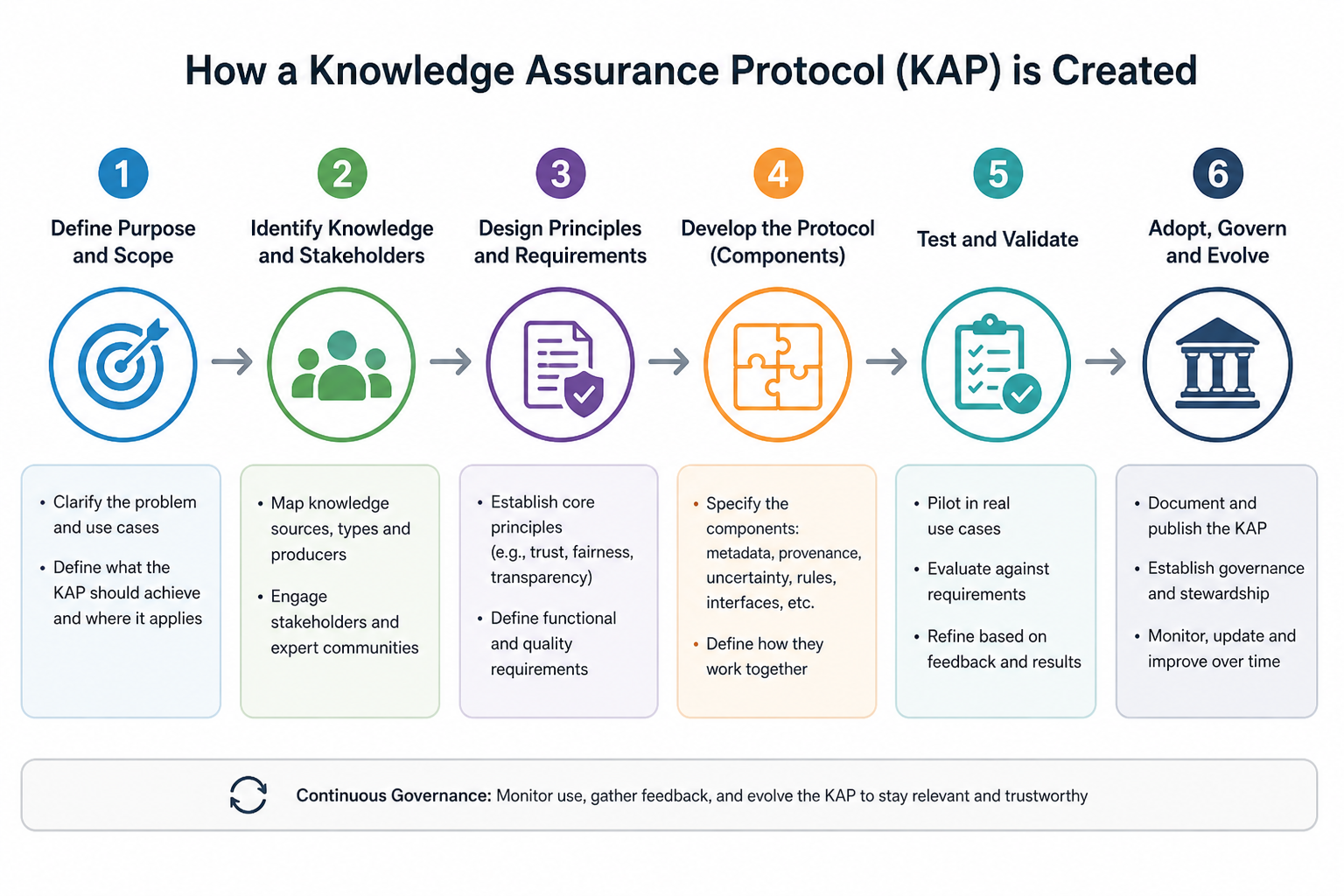
- Define purpose and scope — clarify the problem and use cases, and what the KAP should achieve.
- Identify knowledge and stakeholders — map the sources, types and producers of knowledge, and engage expert communities.
- Design principles and requirements — establish core principles such as trust, fairness and transparency, alongside functional and quality requirements.
- Develop the protocol — specify the components: metadata, provenance, uncertainty, rules and interfaces, and how they work together.
- Test and validate — pilot in real use cases, evaluate against requirements, and refine based on feedback.
- Adopt, govern and evolve — publish the KAP, establish stewardship, and monitor and improve it over time.
In summary
The thread is simple to state, even if the work is not.
- From language, to glossaries.
- To concepts, to ontologies.
- To rules, to protocols.
Each step supports more structured input and output to AI systems. A KAP is the sieve — the layer that decides what passes through and how, so that what comes out the other side is traceable, comparable and honest about its own uncertainty.
If you are working with AI on high-stakes knowledge — in biodiversity, water, infrastructure, or any sector where being wrong is expensive — this is the conversation we would like to have.