Can the British law sector lead on AI?
24 June 2026·8 min read
AI is a wild horse. It is powerful, fast, and currently running where it likes. The question for the British law sector is whether to be dragged along behind it, or to take the reins.
This piece comes out of work tracking how law tech actually works today, through interviews with senior lawyers across large, medium and small British firms, and a workshop on the implications of AI for law and policy. The argument is simple. The British law sector could lead on AI solution design, working with government, rather than following the tech sector and its profit-led software.
Law is text-heavy, but lacks shared standards
Law runs on documents. Yet the processes that move those documents around are rarely standardised or synchronised. The same case is handled differently from firm to firm, and even within a firm the tooling is a patchwork.
When you map the dataflow of a single contested case, the sprawl becomes obvious.
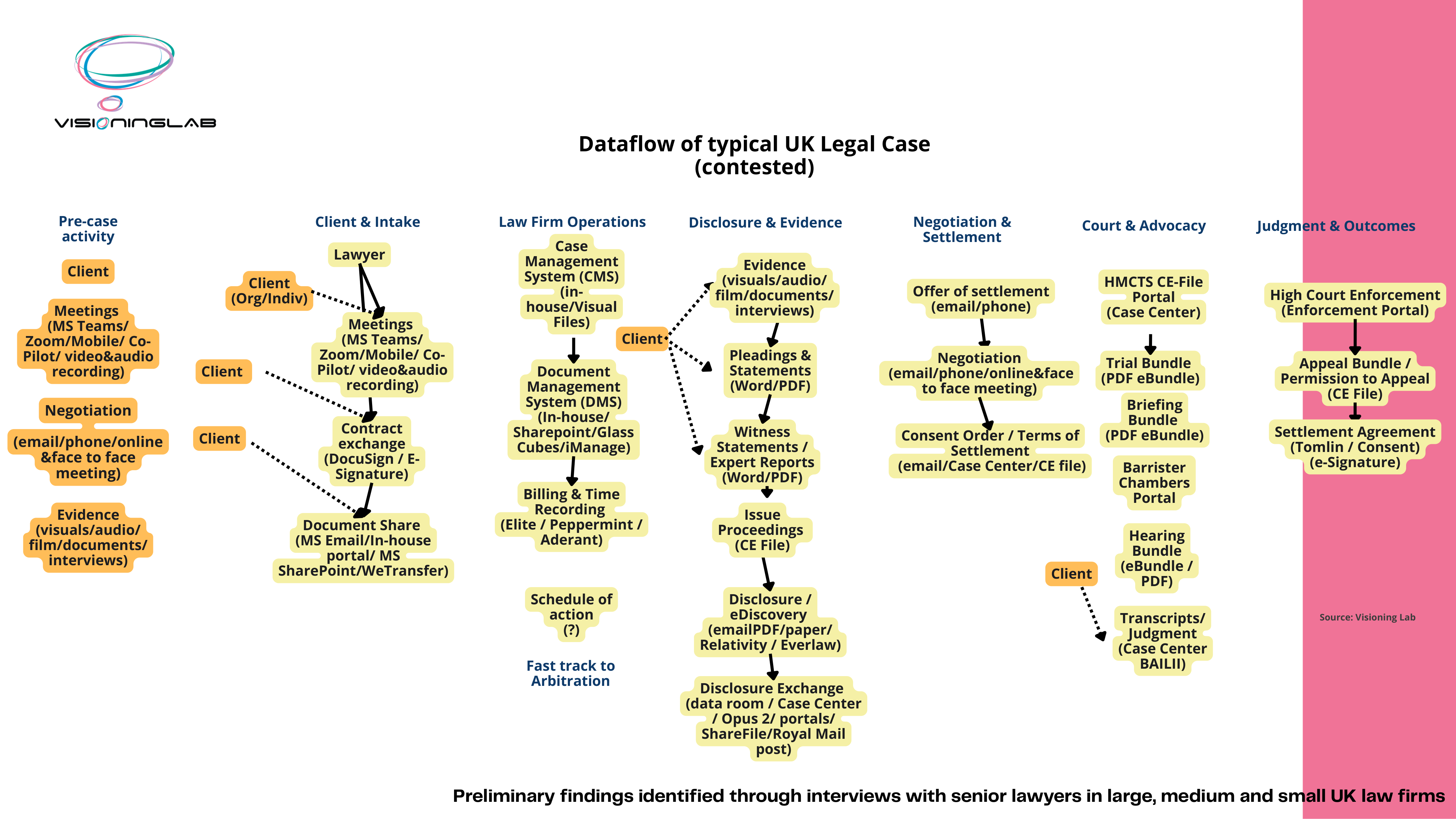
One case touches case management systems, document management systems, e-signature tools, data rooms, court portals, billing software, email and the post. Each stage uses different tools, and the tools rarely talk to each other.
The most striking finding was this. Email, not the document management system, is the real organising function in most lawyers' working lives. And email was never designed for document management. This reliance is causing significant stress and a feeling of overwhelm. Any AI solution that ignores it will fail, because a lawyer's time is chargeable and the move to an AI-enabled process has to be seamless.
Gen AI is already here, and it is leaking
Generative AI is not a future scenario for law. It is already present, and often unmanaged. From solicitors' observations made between October and December 2025:
"I had a case against a litigant-in-person who sent me long emails arguing a position I suspected had been copied from ChatGPT. On several points, the law was wrong. They had no way of knowing it was wrong, and pushed back strongly when corrected."
"Our junior staff are getting answers from Co-Pilot and copying them into documents without checking."
"People are really nervous about AI. The firm is not sure how to implement it so that customers are satisfied. No-one knows what 'right use of AI' looks like."
The danger is not that AI is useless. It is that unreliable output is being adopted into legal work, and eventually into law itself, without provenance, without checking, and without anyone owning the question of what good looks like.
The business model is at stake
There is also a commercial reckoning. As clients gain access to the same AI tools, the value of routine legal work falls. Lawyers' profits may rise steeply at first as they gain a competitive advantage, then drop sharply as mainstream clients self-serve for routine queries and bypass traditional services. The hourly rate, finally, may be dead.
What remains valuable is harder to automate: the ability to think creatively, ask the right questions, challenge the answers, and protect a client's data from AI appropriation. Expertise, confidentiality and human-to-human contact become precious. They are the multidimensional support that comes from decades of experience, not from a single prompt.
A better path: one case, one dataset
The opportunity is that AI enables standardisation, but it needs to be done carefully, and on the sector's own terms. A few concrete first steps emerged from the work:
- Treat the case as one dataset, owned by the client, that runs across organisations. One coherent record that follows the client through every firm and party involved, rather than fragments scattered across email threads and portals.
- Abstract the data management process away from any single piece of software, then look at first principles. How does a case actually travel through the organisation, and how is that being shaped by the tools rather than by the law?
- Develop law ontologies and knowledge graphs to train legal AI systems on reliable, structured foundations.
- Build focused AI tools for well-defined questions, for example "how much does this injury cost?", rather than one black box for everything.
This is where Ontology Maker fits. Law is a highly specific domain with rapidly evolving terminology. Capturing and agreeing that terminology, and the relationships between concepts, is the groundwork that makes legal AI trustworthy rather than plausible-sounding.
Protocols = rules = laws
Ontologies and knowledge graphs give structure. But structure alone does not tell an AI what counts as valid knowledge, or force it to be honest about uncertainty. That is the job of a Knowledge Assurance Protocol.
A KAP is a set of rules for how AI receives and produces knowledge. It defines what counts as valid knowledge, makes provenance and uncertainty explicit, constrains AI to produce traceable and accountable results, and preserves disagreement rather than smoothing it away. It is not a platform, not an ontology, not a dataset. It is a set of principles to be shared with an AI.
For lawyers, the analogy is clear. Protocols are rules. Rules are laws. Designing the rules that govern an AI's use of knowledge is precisely the kind of work the legal profession already does, and a domain where it holds the authority that the tech sector lacks.
From tech spaghetti to AI-enabled synchronicity
Put together, the shift is from tech spaghetti to AI-enabled synchronicity. It moves from a stack of disconnected legal software to a coherent arrangement in which a legal framework of statutes and regulations, common and case law, professional standards and codes of conduct sits above the data, the legal team, the AI and the workflows, governing how they interact.
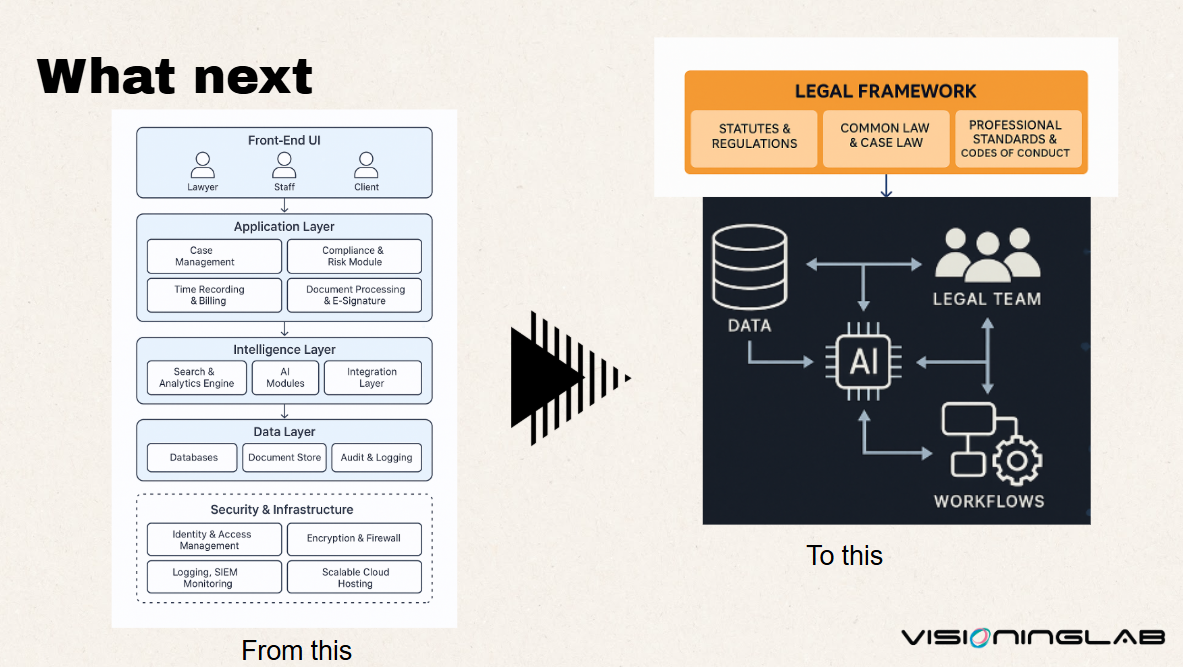
The stretch goal follows naturally. UK law frameworks could sit at the heart of AI ethics engine design. A legal system built over centuries to weigh evidence, manage conflicting claims and assign accountability is well-suited to the task of telling AI systems how to behave with knowledge.
Our Legal AI demonstrator explores some of these ideas in practice.
Taking the reins
The future of law services might be a single prompt that any member of the public can speak to in their own language, asking "I just had a car accident", "my wife wants a divorce", or "design a new law for managing AI", and receiving answers grounded in how matters have genuinely been handled before.
Whether that future is trustworthy depends on who designs the rules behind it. If the British law sector leads, with case-lifecycle data, shared ontologies, and Knowledge Assurance Protocols, AI in law can be accountable rather than merely fast.
However British law is not perfect. It contains inherent bias that needs to be identified and addressed before it can be used as a structured framework for AI systems. Otherwise, we would perpetuate the injustices and inequalities that it currently contains. How this is done is where we are focused next.
That is how you tame a wild horse. Not by chasing it, but by working together to decide where it goes.